
Nhân tiện mọi người có vẻ hào hứng về chủ đề nho nhỏ này và đang viết được, viết nốt kẻo ít hôm lại lười. […]
Tag: Java
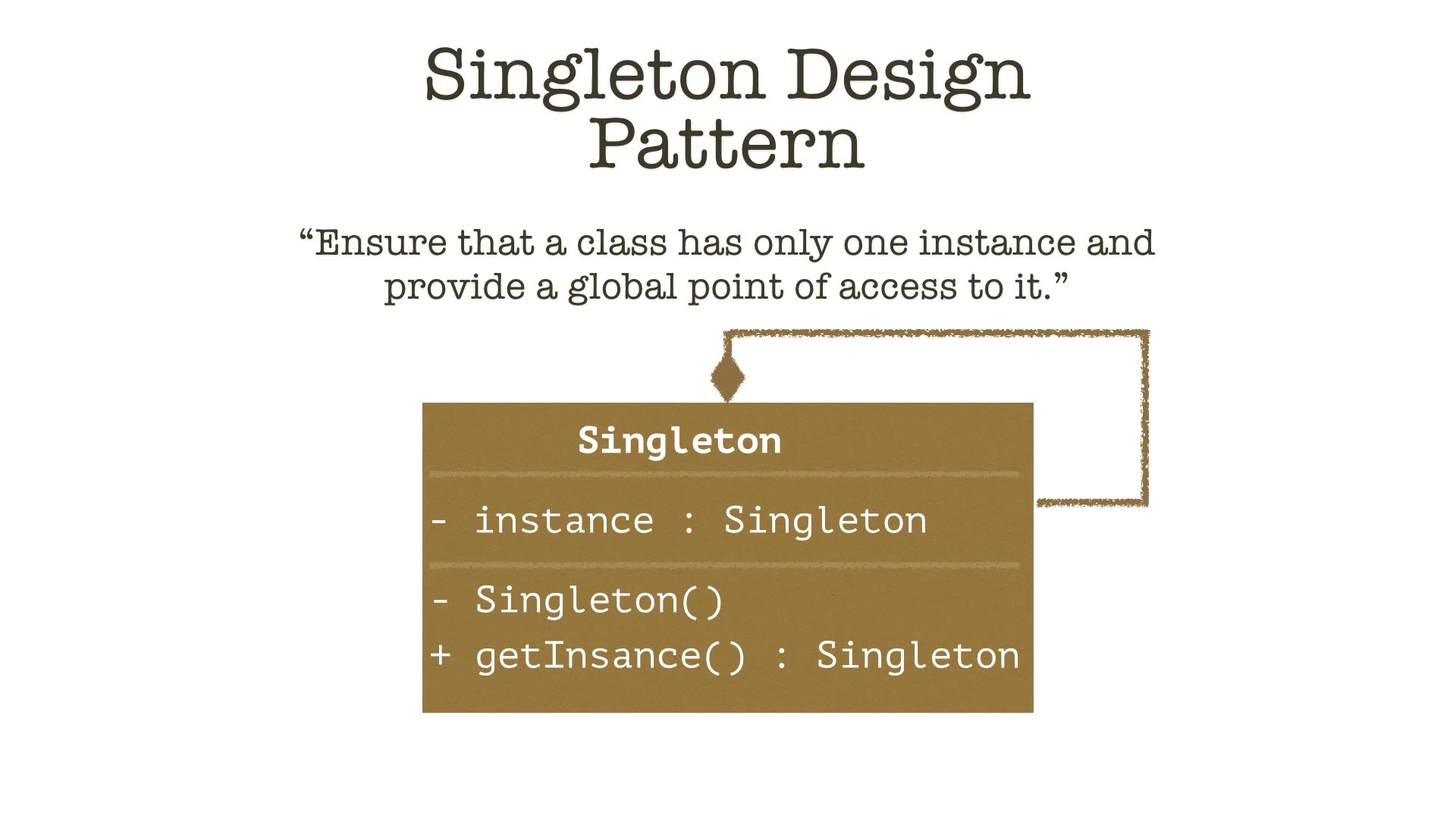
Singleton.threading() in Java
Bài trước về Singleton có thực sự dễ, tôi nhận được vài comment rất chuẩn về cách cài đặt xử lý với theading. Vì bài […]
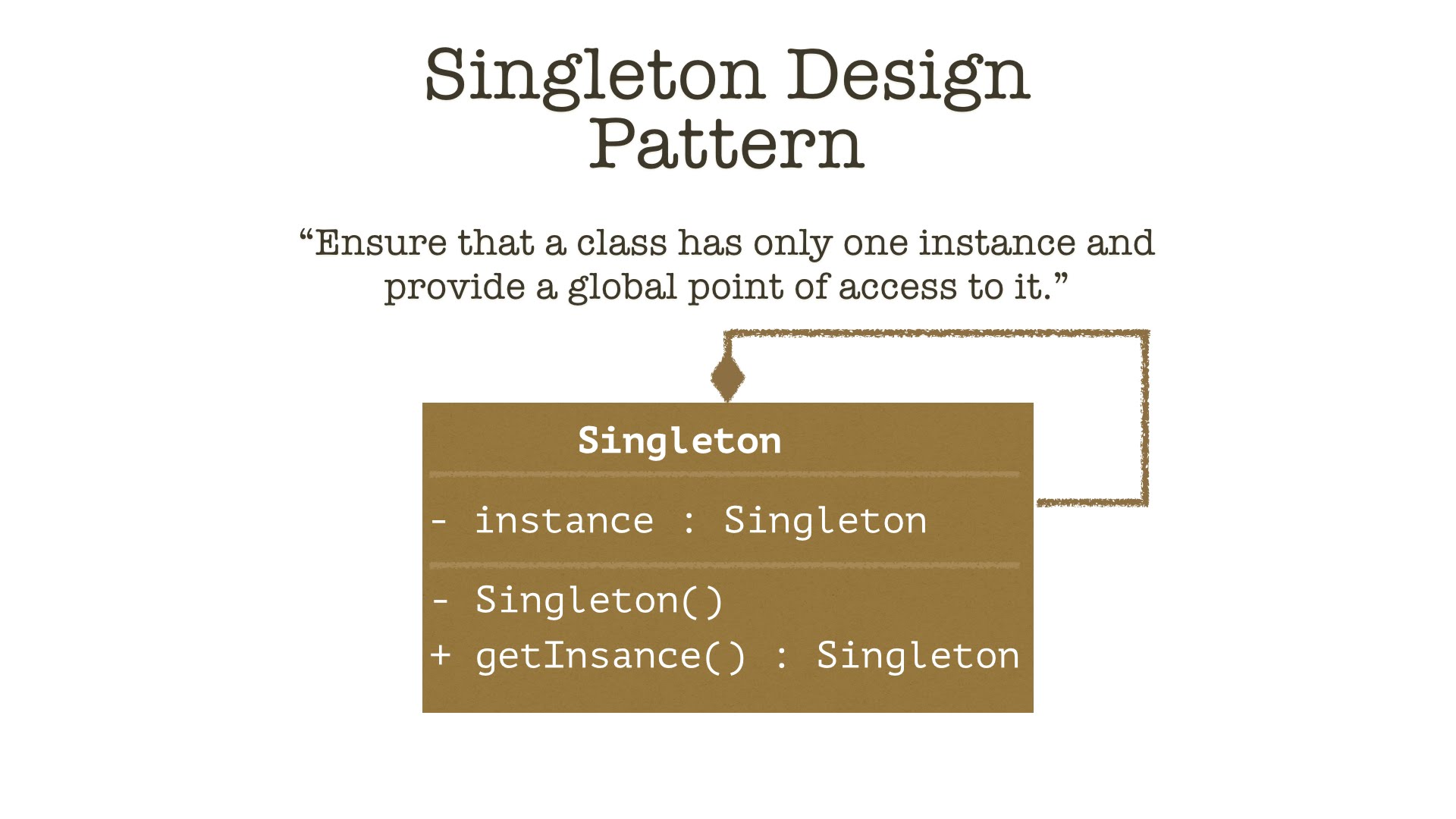
Singleton có thực sự dễ?
Khi nói về Design Patterns, gần 100% những người tôi tiếp xúc đều thực hành Singleton như một design pattern phổ biến và dễ nhất […]
Blockchain explained by simple Java code
Following my problem with KFC system, let’s see another real world problem: The food shop chain with a central hotline/database couldn’t work sometimes because of […]

Abstract. More abstract.
Hôm nay đồng nghiệp hỏi câu này: Tại sao nên viết như #a thay vì #b? /* a. */ List<> list = new ArrayList<>;(); /* […]

Iterating through collection
In my opinion, iterating through a collection is very basic and simple thing because it appears in any developer’s code everyday (of course in the […]