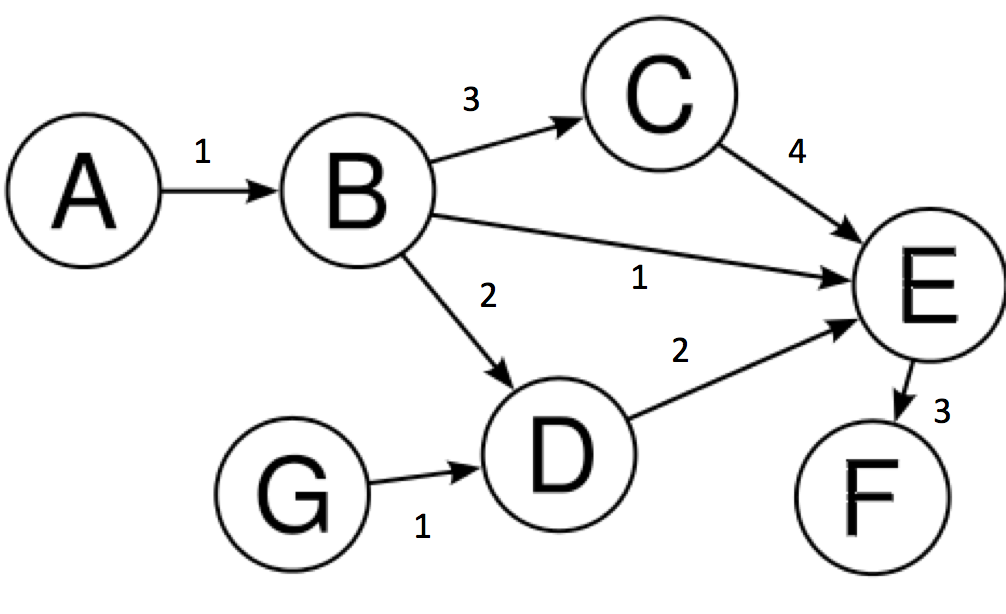
Some days ago, after I published my interview question, my colleague asked me about having the problems weekly and solving them together. And instead of […]
Tag: C#

My interview question
The most important job is recruiting. Yes, it’s totally true. I have spent about a quarter of my time for finding the good guys and […]