Some days ago, after I published my interview question, my colleague asked me about having the problems weekly and solving them together. And instead of theory problem, they should be the real problems that we would face in the daily work. And today we did the first one.
One of the daily problems is making the mock test data as we want to have a lot of data and insert them to a test DB. I’m writing a library that can help my team to generate a random data for test and hope that I can complete and share with you in some next days. But I need to solve the first problem while writing it:
When inserting the data to DB, we need to put them in a correct order to satisfied its constraints. Let’s focus on the reference (foreign key) constraints to make it simple enough. For example, if there are 2 tables Product, Category in the DB, one product should belong to 1 category, so the statements should be:
INSERT INTO Category(Id, Name) VALUES(1, 'Food'); INSERT INTO Product(Id, CategoryId, Name) VALUES(1, 1, 'KFC');
If we change these statements to:
INSERT INTO Product(Id, CategoryId, Name) VALUES(1, 1, 'KFC'); INSERT INTO Category(Id, Name) VALUES(1, 'Food');</pre> <p style="text-align: justify;">
it doesn’t work because the the CategoryId = 1 isn’t existing while the first statement runs. So the problem should be: Giving a clean DB, so we know its schema (and of course, we know all tables’ references), and some INSERT statements, which should be the correct order of these statements? Or which the order of tables should be inserted? For example, it should be (Category, Product) in above sample.
We had a discussion on My Khe (Danang) beach to solve this problem this time, it was very interesting. Finally we had some solutions, and one of them has came up after answering some questions:
1. What are the first tables?
Of course, they are the tables that have no reference to any others. Let call this table set A.
2. What are the next tables?
They are the tables that only refers to the tables in A or itself. Let call this table set B.
3. What are the next tables?
They are the tables that only refers to the tables in A or B or itself. Let call this table set C.
4. The #2 and #3 questions are the same?
Yes.
5. The table set A in #2 answer and (A or B) in #3 answer have the same meaning?
Yes.
So repeat to answer #2 question, we should have a natural approach. The algorithm could be described as: Start with the table that don’t have any reference and add them to table set A, try to find the next tables that their references only belong to A and add them to A in a loop until all table are in A.
And the implementation in C# could be:
private List<string> GetCorrectOrderedTables()
{
// Read schema
var dbReader = new DatabaseReader( _config.ConnectionString, _config.ProviderName );
var _schema = dbReader.ReadAll();
// Build the dependency map
// Key: table name
// Value: List of tables that the table in Key refers to
Dictionary<string, List<string>> dependencyMap = new Dictionary<string, List<string>>();
foreach ( var table in _schema.Tables )
{
if ( !dependencyMap.ContainsKey( table.Name ) )
{
dependencyMap.Add( table.Name, new List<string>() );
}
List<string> refers = dependencyMap[ table.Name ];
refers = table.ForeignKeys.Select( tb => tb.RefersToTable ).ToList();
}
// All the tables we have
List<string> tables = dependencyMap.Select( tb => tb.Key ).ToList();
// Get the tables that have no reference
List<string> orderedTables = dependencyMap.Where( tb => tb.Value.Count == 0 ).Select( tb => tb.Key ).ToList();
foreach ( string table in orderedTables )
dependencyMap.Remove( table );
// Loop: Find and add the next satisfied tables
while ( dependencyMap.Keys.Count > 0 )
{
List<string> satisfiedTables = dependencyMap.Where( tb => tb.Value.Except( orderedTables ).Count() == 0 || ( tb.Value.Except( orderedTables ).Count == 1 && tb.Value.Contains( tb.Key ) ) ).Select( tb => tb.Key ).ToList();
orderedTables = orderedTables.Union( satisfiedTables ).ToList();
foreach ( string table in satisfiedTables )
dependencyMap.Remove( table );
}
return orderedTables;
}
I used DatabaseSchemaReader to get the DB’s schema in this C# code. Of course, you can find another appropriate library in your platform or language as it seems a common problem.
Thank you my friend for giving me the solution and hope that I can get the test data generator done and share with you soon.
Solving a problem, get it done by code and publish it on the blog – all on the beach, it’s such a great experience.

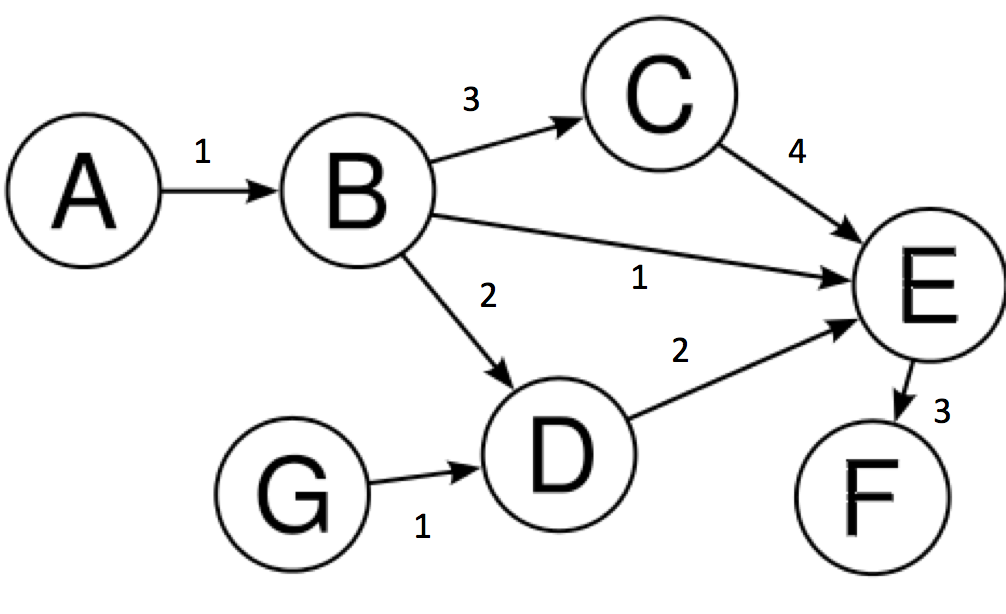
Note: You could see that it’s not just a DB problem itself, and it can be solved by graph or natural algorithm. The DB problem here is just reasonable for having references between the nodes (we can consider that a table is a node, and its references to other tables are the connections in a graph). So you could see the importance of the basic data structure and algorithm to solve any real problem.
I updated the solution and code by the comment of Nguyen Phuc Dat below in case of self-referenced. Dat, thank you guy.